
Meterweise Regalbestände automatisiert erfassen: Geht das schon? Sebastian Ruff verrät, wo KI-Tools Museen unterstützen können, wann Vorsicht geboten ist und wie auch kleine Museen den Einstieg ins Thema finden können.

Sebastian Ruff leitet das Fachteam eCulture beim Stadtmuseum Berlin. Wann immer dort eine neue Ausstellung erdacht wird, achtet der gelernte Historiker und Sammlungskurator darauf, das Digitale von vornherein mitzudenken.
Seit zwei Jahren untersucht er im Rahmen eines hausinternen Forschungsprojekts das Potenzial KI-gestützter Tools für die Sammlungsarbeit – zum Beispiel bei der Verschlagwortung der digitalen Sammlung, der Transkription von Inventarbüchern oder der Analyse von Zeitzeug:innen-Interviews.
Sebastian, für das Stadtmuseum Berlin untersuchst du, welchen Nutzen KI-Tools für die Sammlungsarbeit haben könnten. Wie ist die Idee dazu entstanden?
Sebastian Ruff: Wir haben als Stadtmuseum einen Bestand von 4.5 Millionen Objekten. Sie von Menschenhand zu erschließen, würde Jahrzehnte dauern. Neben Objekten umfasst unsere Sammlung auch Zeitzeug:innen-Interviews mit vielen Stunden Videomaterial. Sie zu transkribieren, zu analysieren, mit Schlagworten zu versehen und in unsere Museumsdatenbank einzuspeisen, wäre mit den vorhandenen personellen Ressourcen ein Ding der Unmöglichkeit. KI-Tools schienen uns eine Möglichkeit zu sein, diesen Aufgaben doch noch beizukommen.

Warum?
Sebastian Ruff: In anderen Sektoren wird Künstliche Intelligenz oft für Aufgaben eingesetzt, die zwar komplex sind, bei denen ausgebildete Fachkräfte aber eigentlich unterfordert sind. Das trifft auch auf einige Tätigkeitsbereiche im Museum zu. Überall da, wo man repetitiv in Datenbanken rumklickt oder wo schnell ein grober Überblick über größere Teile der Sammlung gefragt ist, lohnt es sich, über KI-Lösungen nachzudenken. Aber auch, wer neue Zielgruppen gewinnen möchte, kann mit KI-Tools frische Perspektiven auf die eigenen Bestände entwickeln.
Inwiefern?
Sebastian Ruff: Ein Bestand an Modezeichnungen aus verschiedenen Jahrzehnten kann spannend für eine Community sein, die Inspiration für eigene Zeichnungen sucht – wenn man ihn nach passenden Kriterien durchsuchen kann. KI-gestützte Bilderkennungs-Tools können helfen, Schlagworte zu finden, die mit Farbe, mit Emotionen oder einem bestimmten Stil zu tun haben. Technisch gesprochen also bei der Generierung neuer, ergänzender Arten von Metadaten.
Mit KI Schlagworte generieren: Objekterkennung
Während deiner Recherchen hast du dir Programme angeschaut, die solche Schlagworte automatisiert generieren. Wie funktioniert das?
Sebastian Ruff: Ich habe mich mit zwei technischen Ansätzen befasst, die man separat voneinander betrachten muss – Objekterkennung (meist Englisch als „object detection“) einerseits und Multimodale Large Language Models andererseits. Bei der Objekterkennung wird ein Algorithmus mit sehr vielen Bildern auf das Erkennen von Standard-Bildinhalten trainiert. Wenn er ein Bild untersuchen soll, gibt er viereckige „Fundstellen“ für die Objekte aus – kombiniert mit den Koordinaten des erkannten Objekts und einem prozentualen „confidence“-Wert, der angibt, wie sicher sich der Algorithmus mit seinem Fund ist.
Funktioniert das denn schon gut?
Sebastian Ruff: Ja. Diese Programme richten sich an alle Menschen, die mit großen Bildersammlungen arbeiten und erkennen Standard-Bildinhalte – Menschen, Autos, Bäume, Möbelstücke – sehr zuverlässig. Wer beispielsweise seine Urlaubsbilder nach Sonnenuntergängen durchsuchen möchte, ist mit ihnen also gut bedient.
Kannst du ein paar Beispielprogramme nennen?
Sebastian Ruff: Die letzten Versionen der YOLO-Serie, YOLO 8 und YOLO 9, arbeiten sehr präzise. Auch Faster R-CNN ist sehr zuverlässig.
Wofür eignet sich dieser Ansatz im Museum?
Sebastian Ruff: Mit dieser Methode kann man sehr gut historische Fotos oder Postkarten untersuchen und nach Inhalten klassifizieren. Wenn Kurator:innen anfangen, eine Ausstellung zu konzipieren, wollen sie oft erstmal viel Material sichten. Auf Bitten wie „Gib mir mal alle Bilder mit Autos drauf“ kann man mithilfe dieser Programme viel schneller eingehen.
Modellprojekt
Von 2020-2023 untersuchte auch das Ludwig Forum in Aachen das Potenzial von KI für die Sammlungsarbeit.
Was zeichnet diese Programme noch aus?
Sebastian Ruff: Die Objekterkennungs-Modelle sind recht klein und können auch auf dem heimischen Rechner ausgeführt werden, und das sogar offline. Mit ihnen kann man also die Kontrolle über die eigenen Daten behalten. Mit ausreichend Fachwissen kann man diese Modelle auch trainieren, zum Beispiel mit 100 Bildern des Fernsehturms. Sobald es zu museumsspezifisch wird und Objekte entweder sehr speziell sind oder außerhalb ihres alltäglichen Kontextes abgebildet werden, versagen sie aber.
Einblick in die Ergebnisse, die die Programme liefern:












Mit anderen Worten: Wenig Hoffnung für alle, die gerne kilometerweise Regalbestände automatisiert erfassen und klassifizieren würden?
Sebastian Ruff: Genau. Es gibt im Bereich Objekterkennung bisher kein KI-Modell, das spezifisch für den Umgang mit vielfältigen Museumsobjekten trainiert wurde und Schlagworte liefert, die man ohne sorgfältige Überprüfung für die wissenschaftliche Museumsarbeit nutzen kann. Ich sehe auch nicht, dass gerade jemand an so einer „Museums-KI“ arbeitet.
Mit KI Schlagworte generieren: Multimodale LLMs
Was versteckt sich hinter dem zweiten Ansatz, den Multimodalen Large Language Models?
Sebastian Ruff: Das sind Modelle, die mit gigantischen Datenmassen trainiert wurden, die Bilddateien mit zugehörigen Bildbeschreibungen enthalten. Sie verstehen im Prinzip jedes Bild und haben das größte Potential für die Verwendung im Kulturkontext – zumal sie auch von IT-Lai:innen per natürlicher Sprache bedient werden können.
Worauf muss man bei der Arbeit mit MLLMs achten?
Anschau-Tipp:
Das BMBF-geförderte Qurator-Projekt entwickelt Plattformlösungen zur KI-gestützten Kuratierung digitaler Inhalte
Sebastian Ruff: Diese Modelle sind sehr groß und ressourcenhungrig – und sie laufen nicht lokal, sondern über die Cloud. Alle Inhalte, die man mit ihrer Hilfe verschlagwortet, landen zumindest temporär auf den Servern der Anbieter. Die können sie dann für das Training ihrer kommerziellen, proprietären Systeme nutzen. Das ist eines der größten ethischen Bedrängnisse, vor denen wir hier stehen.
Wie bist du in deinen Tests mit diesem ethischen Problem umgegangen?
Sebastian Ruff: Wir haben für unsere Versuche ausschließlich gemeinfreie Bilder und solche verwendet, an denen wir alle Rechte haben. Außerdem haben wir bei der Auswahl darauf geachtet, den Bias-belasteten Bildkorpus der Testdaten nicht durch noch mehr problematisches Material zu erweitern. Wir haben also beispielsweise Bilder ausgeklammert, die koloniale Szenen zeigen.
Lesetipp
Mehr zu Biases bei Bild-KIs in unserem Einstiegstext:
Von diesen ethischen Bedenken abgesehen: Welche MLLMs liefern gerade die besten Ergebnisse?
Sebastian Ruff: Das GPT4-Modell von OpenAI ist hier immer noch der Benchmark. Aber auch die „Claude“-Modelle von Anthropic sowie Google Gemini liefern sehr überzeugende Ergebnisse. Im Open Source-Bereich haben die Llava-Modelle und CogVLM2 die Nase vorn und können den kommerziellen Modellen teils durchaus das Wasser reichen.
Einblick in die Ergebnisse, die die Programme liefern:

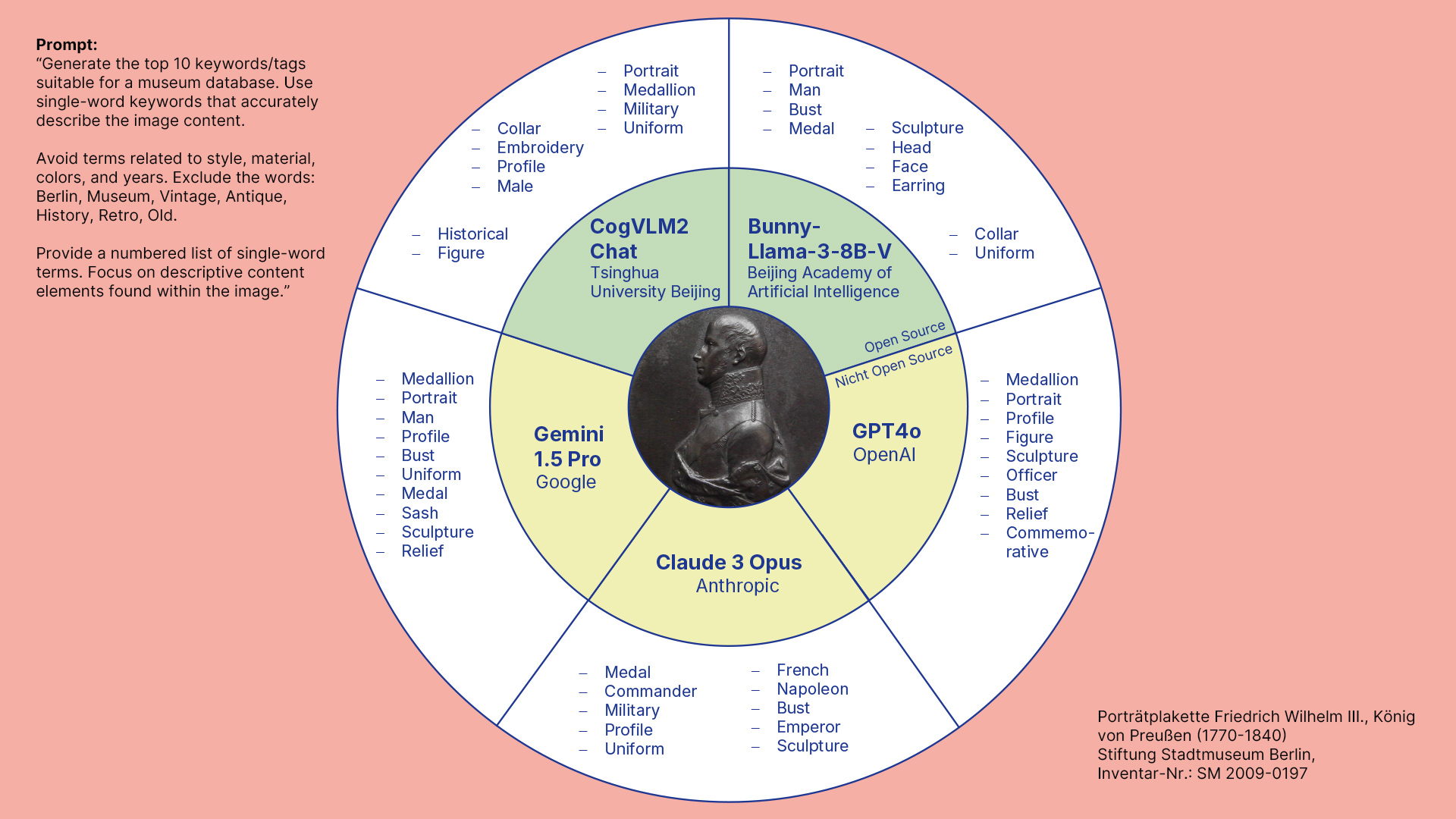

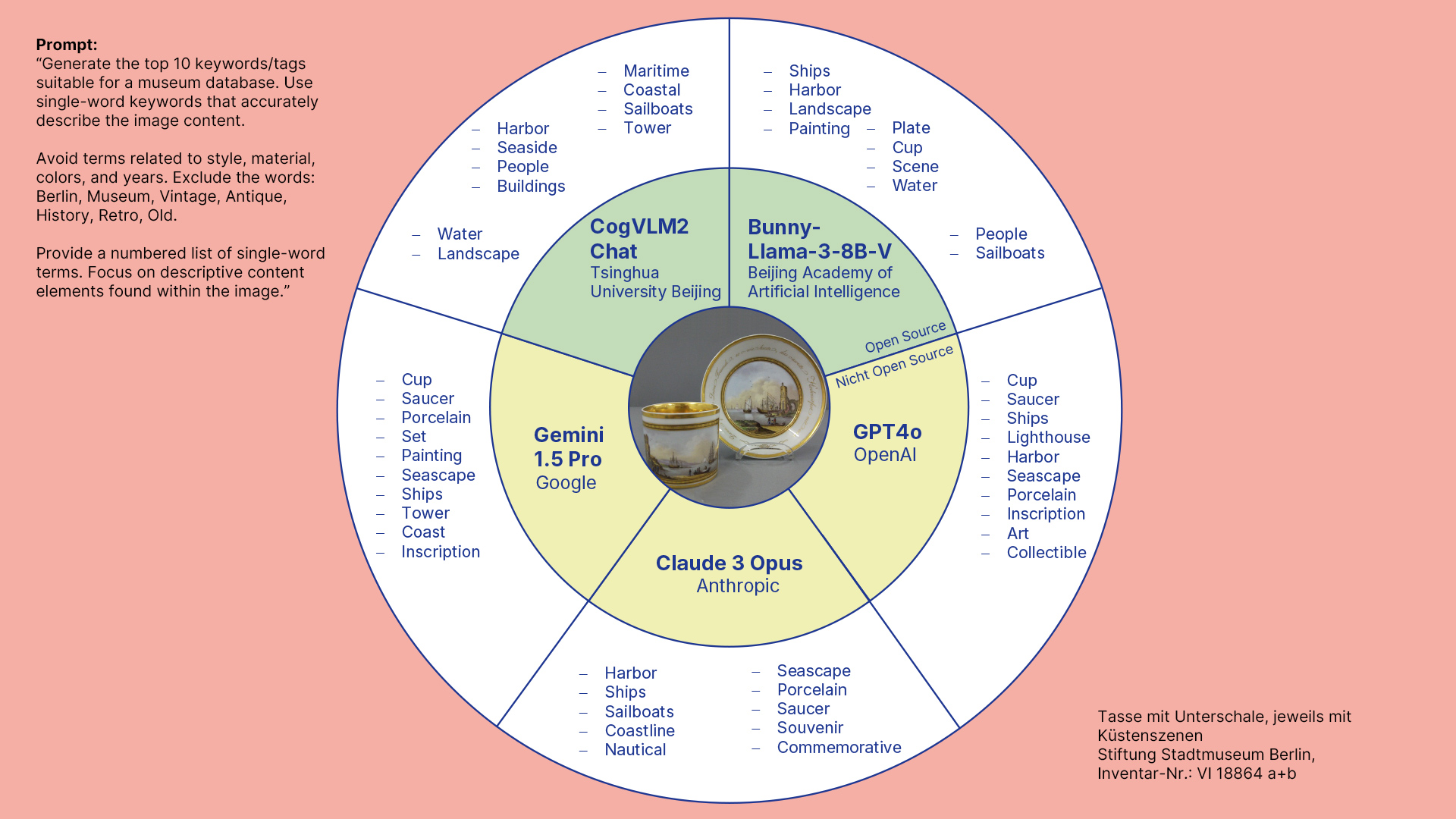
Die Schlagwortvorschläge der Objekterkennungsprogramme sind also nicht museumsspezifisch genug und MLLMs will man lieber nicht auf seinen gesamten Bestand loslassen. Wie geht ihr nun mit den Ergebnissen aus euren Tests um?
Sebastian Ruff: Als Museum haben wir die Aufgabe, soviel wie möglich von dem Kulturgut, das wir verwalten, sichtbar und zugänglich zu machen. Jedes Metadatum, das eine Veröffentlichung ergänzt und verbessert, ist erstmal ein gutes Metadatum. Wir haben deshalb vor, KI-generierte Schlagworte auch für die Ergänzung der Online-Sammlung zu verwenden.
Eine aktuelle Studie zeigt, dass Museen großes Vertrauen in der Bevölkerung genießen. Ihre Arbeit wird als objektiv und unparteiisch wahrgenommen. Wie verhindert man, dass der Einsatz von KI dieses Vertrauen in Gefahr bringt?
Sebastian Ruff: Transparenz ist das oberste Gebot. Wir kennzeichnen alle KI-generierten Inhalte und vermischen sie nicht mit menschlich generierten Inhalten. Die Ergebnisse unserer Verschlagwortung würde ich gerne in einem experimentellen Umfeld veröffentlichen, einem digitalen Lab beispielsweise. Das sollte meines Erachtens ohnehin viel häufiger passieren.
Dass man als Kulturinstitution schneller mit ersten Ergebnissen an die Öffentlichkeit geht, ohne auf den Moment zu warten, in dem man sich zu 100 Prozent hinter sie stellen kann?
Sebastian Ruff: Genau. Es bräuchte viel mehr eine Kultur des Ausprobierens beim Thema KI – und dafür müsste sich aber auch etwas an den Rahmenbedingungen ändern. Es wäre schön, wenn nicht jede Kulturinstitution eine eigene technische Infrastruktur aufbauen müsste, um erste Experimente mit KI zu machen. Ein KI-Spielplatz für die Kultur, das wär’s doch.
Wie gelingt der KI-Einstieg für kleine Museen?
Klingt toll. Da wir dort aber noch nicht sind: Was wären deine Tipps für kleinere Institutionen, die sich dem Thema KI annähern wollen?
Sebastian Ruff: Zuerst sollte man sich fragen, ob man dafür wirklich Zeit hat. Es braucht mindestens eine Person in der Institution, die technische und begriffliche Grundkenntnisse erarbeitet. Der nächste Punkt kann eine Fehlstellenanalyse sein: Wo haben wir Lücken in unseren Daten? Haben wir Dinge im Regal stehen, die gar nicht verzeichnet sind, geht es also um Grunddaten, die fehlen? Oder fehlen uns normierte Personen- und Ortsdaten, um unsere Bestände an die Gemeinsame Normdatei anzudocken?
Wie kann es nach dieser Analyse weitergehen?
Sebastian Ruff: Nach der Analyse sollte man sich ein isoliertes Problem rausnehmen, das nicht von Menschenhand zu lösen ist. Die Frage, ob es mit KI zu lösen ist, sollte man dann versuchen, anhand eines repräsentativen Querschnitts der eigenen Sammlung zu beantworten. 100 Objektdatensätze – möglichst aus unkritischen, gemeinfreien Daten – reichen dabei völlig aus. Das Thema Verschlagwortung eignet sich sehr gut zum Einstieg.
Wie finde ich als Kultureinrichtung dann die Anwendungen, die sich für meine Zwecke wirklich eignen?
Sebastian Ruff: Es ist immer eine gute Idee, erstmal IT-Expertise im eigenen Haus anzufragen oder die Hand in Richtung Universitäten auszustrecken. Kulturinstitutionen sind hier gern gesehene Praxispartner bei KI-Forschungsprojekten. Auch den Anbieter der eigenen Museumsdatenbank kann man mal fragen, ob er KI-gestützte Ergänzungen für die Sammlungsarbeit anbietet.
Lesetipp
Forschungskooperation des Deutschen Meeresmuseum und der TH Köln
KI als Servicekraft: Intelligente Dialogsysteme in Kulturinstitutionen
Für eine allererste Orientierung beim Thema KI kann man auch gut den eigenen Landesmuseumsverband anfragen – oder in Berlin direkt die Fachgruppe Digitale Transformation. Erst, wenn sich auf diesem Wege nichts ergibt, sollte man sich Unterstützung auf dem freien Markt einkaufen.
In welchen Schritten kann man hier vorgehen – von einfach bis aufwendig?
Sebastian Ruff: Ein einfacher Ansatz wäre die Arbeit mit einem Bildkatalog-Programm, das Plugins zu Google Vision oder anderen MLLMs anbietet. Adobe Lightroom käme hier infrage – zum Beispiel mit dem Plugin Any Vision, das ich empfehlen kann. Dabei sind die Kosten überschaubar. Diese Plugins schicken deine Bilder zu Google oder einem anderen Anbieter, fragen dort Schlagworte, Bildbeschreibungen und Farben ab und importieren sie strukturiert zurück in deinen Lightroom-Bildkatalog. Bei diesem Ansatz verheiratet man sich natürlich mit großen Datenkonzernen. Von Standalone-Programmen namhafter Hersteller wie Nero oder ACDSee kann ich übrigens nur abraten. Sie haben im Test die schlechtesten Ergebnisse geliefert.
Was wären aufwendigere Ansätze?
Sebastian Ruff: Wer etwas mehr Ressourcen hat, kann mit der API eines Anbieters wie Open AI, Google, Anthropic oder auch freien Modellen wie Llava arbeiten. Diese Lösungen kann man zum ersten Test auch in den sogenannten „Playgrounds“ der Anbieter ausprobieren. Für die Anbindung an die eigene Datenbank kann man die IT-Abteilung des Hauses oder die Mitarbeiter:innen der eigenen Museumsdatenbank anfragen. Am aufwendigsten, aber auch lohnendsten wäre es, ein freies Modell selber zu trainieren, um eine Museums-KI zu bauen.
Zeitzeug:innen-Interviews mit KI erschließen
Wenden wir uns einem anderen Bereich deiner Arbeit zu, in dem du mit KI-gestützten Tools arbeitest. Der Erschließung von Zeitzeug:innen-Interviews. Zunächst mal: Um was für Material handelt es sich dabei?
Sebastian Ruff: Das sind mehr als 100 Stunden Video-Aufnahmen aus dem künstlerischen Projekt „Berliner Zimmer“, das wir gemeinsam mit der Künstlerin Sonya Schönberger umsetzen. In den Videos befragt sie Zeitzeug:innen aus Berlin zu unterschiedlichen historischen Zusammenhängen und ihren zugehörigen Erinnerungen. Material, das wir von Menschenhand unmöglich hätten zugänglich machen können in einer Weise, die unseren Ansprüchen als Museum genügt.
Was ist bei deinen Recherchen herausgekommen?
Sebastian Ruff: Die meisten Firmen, die Audio- und Videotranskription anbieten, sitzen im Nicht-EU-Ausland, sehr viele in den USA, einige auch in China. Und die haben als Zielgruppen nicht Kulturinstitutionen im Kopf, sondern vor allem Content Creator. Also alle, die selber Videos erstellen und sich Arbeit ersparen wollen, deren Ergebnisse aber nicht den Anspruch haben, den wir als Museum im archivarischen Umgang mit audiovisuellen Medien haben. Mit Aureka sind wir dann aber auf einen Partner gestoßen, der sich bestens für unsere Zwecke eignet.
Wer steckt dahinter?
Sebastian Ruff: Aureka ist ein Berliner Start-up mit universitärem Background, das auch selbst den Anspruch hat, Künstliche Intelligenz in den Dienst von Forschung und Journalismus zu stellen. So etwas gibt es selten und wir haben uns sehr über die Entdeckung gefreut.
Kannst du einmal skizzieren, wie die Erschließung eines Interviews in eurem Fall abläuft?
Sebastian Ruff: Den Start machen wir in unserer eigenen Museumsdatenbank Daphne. Dort legen wir das Interview als digitales Museumsobjekt an, das heißt, es bekommt eine Inventarnummer und einige Grunddaten – etwa zum Jahr der Aufzeichnung und zur interviewten Person.
Dann werden die Interviews mit ihren Metadaten als kleingerechnetes Video bei Aureka hochgeladen. Dort setzt sich ein automatisierter Prozess in Gang, der das Ergebnis von einem Jahr gemeinsamer Tüftelei mit den Kolleg:innen von Aureka ist: Zunächst entsteht automatisiert ein Transkript, das wir dann händisch korrigieren können. Dieses Transkript ist dann die Basis für eine ganze Reihe von automatisch erstellten Produkten.
Welche sind das?
Sebastian Ruff: Aureka erstellt Untertitel in Deutsch und Englisch mit KI-generierten Timings, eine Zusammenfassung des Interviews auf 300 Zeichen und eine Reihe von Schlagworten, die das Interview inhaltlich beschreiben. Diese Schlagworte werden außerdem mit der Gemeinsamen Normdatei (GND) abgeglichen, um die erschlossenen Interviews anschlussfähig an die Bestände anderer Häuser zu machen. Dieses Set aus Metadaten wird dann exportiert und in unsere Datenbank importiert.
Wieviel Arbeit müsst ihr dann noch in die händische Redaktion der automatisch erstellten Ergebnisse stecken?
Sebastian Ruff: Tatsächlich ist die Qualität inzwischen so gut, dass wir die Ergebnisse fast unbesehen übernehmen. Das ist ein Schritt, der Mut erfordert hat und über den wir hausintern lange debattiert haben. Am Ende war aber klar: Wenn das Ziel des ganzen Projekts ist, Ressourcenprobleme zu bewältigen, können wir nicht aus einer Restsorge heraus Redaktionsschleifen einbauen, obwohl wir mit den Ergebnissen zufrieden sind.
Das klingt, als wärt ihr nicht mehr weit von einer Veröffentlichung der Ergebnisse entfernt.
Sebastian Ruff: Das ist richtig. Bis Ende 2024 werden wir alle bestehenden Zeitzeug:innen-Interviews in der Datenbank haben – inklusive ihrer Datensätze.
Handschriften mit KI erschließen
Der dritte Teil deines Projekts besteht in der KI-gestützten Erschließung von Handschriften. Kannst du hier schon ähnliche Erfolge vermelden?
Sebastian Ruff: Was das Finden einer passenden Anwendung angeht, auf jeden Fall. Hier setzen wir auf die browserbasierte Plattform Transkribus. Die ist – ähnlich wie Aureka – eine Ausgründung aus einem universitären Umfeld und hat ihre Kernkompetenz beim Erschließen von schriftlichem Kulturgut. Es gibt zwar noch ein paar Mitbewerber, aber wir haben uns hier bewusst für das etablierte Angebot entschieden.
Wie weit seid ihr hier schon mit eurer Arbeit?
Sebastian Ruff: Wir sind sehr froh, auf Transkribus gestoßen zu sein, müssen aber die praktische Umsetzung aufs nächste Jahr schieben. Das ist auch eines meiner Learnings aus den letzten Jahren. Ich würde niemandem empfehlen, mehr als ein KI-Projekt pro Jahr anzugehen. Unser hausinternes Forschungsprojekt haben wir dementsprechend auch gerade verlängert.
Das Interview führte Thorsten Baulig.